This post covers Big Data & Hadoop Overview, Concepts, Architecture, including Hadoop Distributed File System (HDFS).
This post is for beginners who are just starting to learn Hadoop/Big Data and covers some of the very basic questions like What is Big Data, How is Haddop related to Big Data.
In next follow up post, I’ll cover what thing you must learn & roadmap to Start learning Big Data & Hadoop.
What is Big DATA?

- Big data is a term described for a huge amount of Data, both Structured & Un-Structured.
- Structured Data refers to highly organised data like in Relational Databases (RDBMS) where infomraiton is stored in Tables (rows & columns). Structured Data is easy to search for end user or search engines.
- Unstructured Data, in contrast, doesn’t fit into traditional rows & columns structure of RDBMS. Example of unstructured data is email, videos, audio files, web pages, social media messages etc
Characteristics of Big Data
Big Data can be defined by following characteristics
- Volume: The Amount of Data matters in Big Data. You’ll deal with huge amount of unstructured data that is low in density. The volume of data may range from Terabytes to Petabytes. Size determines if data can be considered as Big Data or Not.
- Velocity: is the fast rate at which data is received and processed. Big Data is often available in real time.
- Variety: refers to many types of data that are available, both structured & unstructured i.e. Audio, Video, Text Messages, Images. This helps to a person who analyses big data to make a meaningful result.
- Veracity: refers to Data Quality of captured information, affecting the accurate analysis.
huge collection of data sets that can’t be stored in a single machine. Big data is huge-volume, fast-velocity, and different variety information assets that demand innovative platform for enhanced insights and decision making.
The Problem (Big Data) & Solution (Hadoop)
Big Data is massive, poorly or less structured, unwieldy data beyond the petabyte. This data is not able to understand by a human in full context.
Hadoop is the most popular and in-demand Big Data tool that solves problems related to Big Data.
Here is the timeline for Hadoop from Apache Software Foundation

What is Hadoop?
Hadoop is an open-source framework that allows to store and process big data in a distributed environment across clusters of computers using simple programming models.
Hadoop is designed to scale up from single servers to thousands of machines, each offering local computation and storage.

Hadoop Components
Hadoop has three main components Hadoop Distributed File System (HDFS), Hadoop MapReduce and Hadoop Yarn
- A) Data Storage -> Hadoop Distributed File System (HDFS): A distributed file system that provides high-throughput access to application data.
- B) Data Processing-> Hadoop MapReduce: This is a YARN-based system for parallel processing of large datasets. The term MapReduce actually refers to the following two different tasks that Hadoop programs perform:
- The Map Task: This is the first task, which takes input data and converts it into a set of data, where individual elements are broken down into tuples (key/value pairs).
- The Reduce Task: This task takes the output from a map task as input and combines those data tuples into a smaller set of tuples. The reduce task is always performed after the map task
- C) Scheduling & Resource Manageemnt-> Hadoop YARN: This is a framework for job scheduling and cluster resource management.
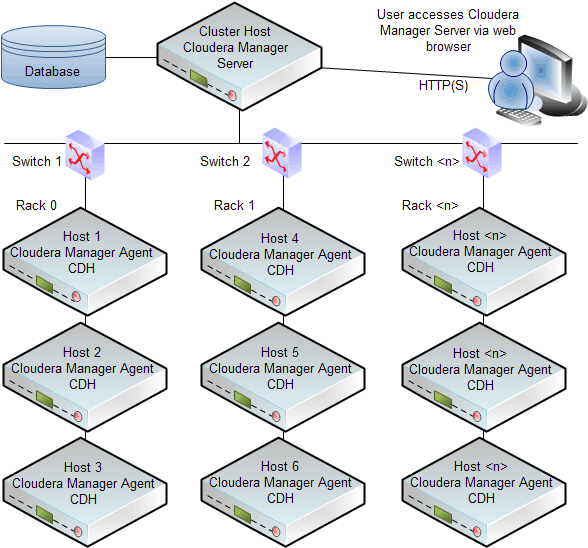
HDFS Architecture
 The main components of HDFS are NameNode and DataNode.
The main components of HDFS are NameNode and DataNode.
- NameNode: It is the master daemon that maintains and manages the DataNodes (slave nodes). It records the metadata of all the files stored in the cluster, e.g. location of blocks stored, the size of the files, permissions, hierarchy, etc.
- DataNode: These are slave daemons which run on each slave machine. The actual data is stored on DataNodes. They are responsible for serving read and write requests from the clients. They are also responsible for creating blocks, deleting blocks and replicating the same based on the decisions taken by the NameNode.
This post is from our Big Data Hadoop Administration Training, in which we cover HDFS Overview & Architecture, Cloudera, Hive, Spark, Cluster Maintenance, Security, YARN and much more.
If you are looking for commonly asked interview questions for Big Data Hadoop Administration then just click below and get that in your inbox or join our Private Facebook Group dedicated to Big Data Hadoop Members Only.
In next follow up post, I’ll cover what thing you must learn & roadmap to Start learning Big Data & Hadoop.
References & Related
- Big Data on Wikipedia
- What is Big Data from Oracle
- Apache Hadoop
- Step by Step Training on Hadoop & Cloudera

The post Big Data & Hadoop Architecture, Components & Overview appeared first on Oracle Trainings.










































 There were 70 questions and 105 mins were allocated and most of the questions were based on the designing architecture of various infrastructure components using OCI resources. If you have clear understanding and scope of various services it is easy to answer the questions and clear the exam.
There were 70 questions and 105 mins were allocated and most of the questions were based on the designing architecture of various infrastructure components using OCI resources. If you have clear understanding and scope of various services it is easy to answer the questions and clear the exam.






















