This blog post will go through some quick tips including Q/A and related blog posts on the topics that we covered in the Azure Data Engineer Day 2 Live Session which will help you gain a better understanding and make it easier for you to learn the Azure Data Engineer Training Program clear the [Dp203] Certification & get a better-paid job
in the Day 2Live Session of the[DP-203] Microsoft Data Engineering Training Program, we covered the concepts of Azure data factory and learned how to Design and Implement the serving layer, along with Data engineering considerations for source files.
We also covered step by step Lab 2: In this lab, we interacted with 1 compute technologies related to data i.e. Azure Data Factory, and 1 activity on source files.
>Azure Data Factory
In today’s data-driven world, big data processing is a critical task for every organization. To unlock transformational insights, data engineers need services that are built to simplify ETL as well as handle the complexities and scale challenges of big data integration. With Azure Data Factory, it is fast and easy to build code-free or code-centric ETL and ELT processes. In this scenario, learn how to create code-free pipelines within an intuitive visual environment.
Features:
1. Accelerate data transformation with code-free data flows
2. Rehost and extend SSIS in a few clicks
3. Ingest all your data with built-in connectors
Source: Microsoft
>Azure Data Studio
Azure Data Studio is a cross-platform database tool for data professionals using on-premises and cloud data platforms on Windows, macOS, and Linux. Azure Data Studio offers a modern editor experience with IntelliSense, code snippets, source control integration, and an integrated terminal. It’s engineered with the data platform user in mind, with the built-in charting of query result sets and customizable dashboards. Use Azure Data Studio to query, design, and manage your databases and data warehouses, wherever they are – on your local computer or in the cloud.
Source: Microsoft
Lab: Design and Implement the serving layer
This module teaches how to design and implement data stores in a modern data warehouse to optimize analytical workloads. The student will learn how to design a multidimensional schema to store fact and dimension data. Then the student will learn how to populate slowly changing dimensions through incremental data loading from Azure Data Factory.
In this module, the student will be able to:
Design a star schema for analytical workloads (OLAP)
Populate slowly changing dimensions with Azure Data Factory and mapping data flows
So, here are some FAQs asked during the Day 2 Live session from Module 2 and Module 3 Of DP203.
Q1. Is the Primary Key present in the dimension table and the foreign key is present in the fact table?
A. Yes, it is, Because the dimension table consists of attributes that have only single entries. While fact tables are references from the dim table. For example, a customer’s name and address are stored in a dimension table and updated only when the customer’s profile changes. To minimize the size of a large fact table, the customer’s name and address don’t need to be in every row of a fact table.
Q2. What are the types of dimensions? A. Dimension tables describe business entities—the things you model. Entities can include products, people, places, and concepts including time itself.
Q3. Which is the most optimized model? A. The snowflake schema and its aim to normalize the data to reduce the repetition in the data and therefore space is taken up by the data, leading to fewer IO requests making it quicker to retrieve the data in queries.
Q4. If Azure data factory and synapse pipelines have the same functionality then which one to choose and why to choose?
A. If your requirement only data movement and transformation then use Azure data factory and For Analytics capabilities go with synapse because Azure synapse analytics is an umbrella service that provides analytical workspace along with other services
Q5. How to choose between slowly changing dimension types? A. Type 1 SCD A. A Type 1 SCD always reflects the latest values, and when changes in source data are detected, the dimension table data is overwritten. This design approach is common for columns that store supplementary values, like the email address or phone number of a customer. When a customer’s email address or phone number changes, the dimension table updates the customer row with the new values. It’s as if the customer always had this contact information. The key field, such as CustomerID, would stay the same so the records in the fact table automatically link to the updated customer record.
Source: Microsoft
Type 2 SCD
A Type 2 SCD supports versioning of dimension members. Often the source system doesn’t store versions, so the data warehouse load process detects and manages changes in a dimension table. In this case, the dimension table must use a surrogate key to provide a unique reference to a version of the dimension member. It also includes columns that define the date range validity of the version (for example, StartDate and EndDate) and possibly a flag column (for example, IsCurrent) to easily filter by current dimension members.
Source: Microsoft
Type 3 SCD
A Type 3 SCD supports storing two versions of a dimension member as separate columns. The table includes a column for the current value of a member plus either the original or previous value of the member. So Type 3 uses additional columns to track one key instance of history, rather than storing additional rows to track each change like in a Type 2 SCD. This type of tracking may be used for one or two columns in a dimension table. It is not common to use it for many members of the same table. It is often used in combination with Type 1 or Type 2 members.
Source: Microsoft
Type 6 SCD
A Type 6 SCD combines Type 1, 2, and 3. When a change happens to a Type 2 member you create a new row with appropriate StartDate and EndDate. In Type 6 design you also store the current value in all versions of that entity so you can easily report on the current value or the historical value. Using the sales region example, you split the Region column into CurrentRegion and HistoricalRegion. The CurrentRegion always shows the latest value and the HistoricalRegion shows the region that was valid between the StartDate and EndDate. So for the same salesperson, every record would have the latest region populated in CurrentRegion while HistoricalRegion works exactly like the region field in the Type 2 SCD example.
Source: Microsoft
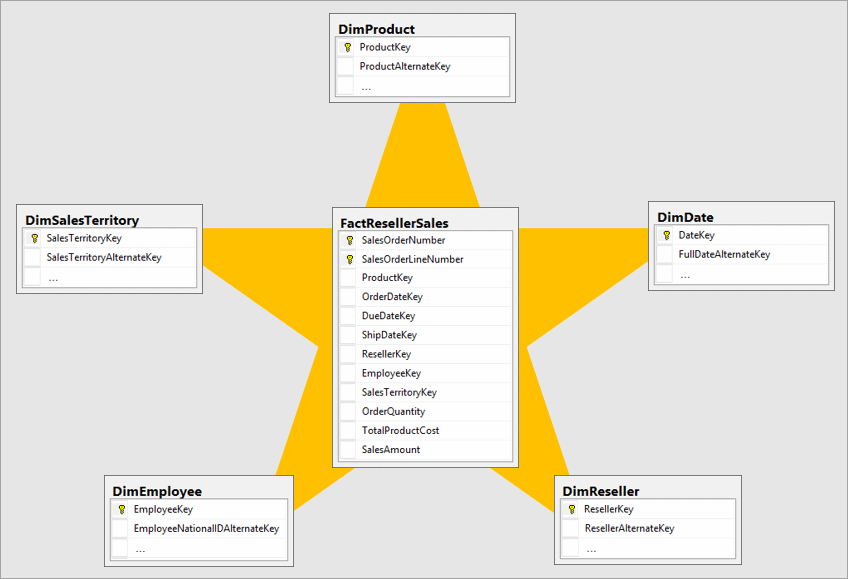
Q6. What is star schema?
A. The star schema as the name suggests is a star structured type of data warehouse schema. In this schema center of the star consist of a fact table and a number of dimensions associated with this fact table, this schema is also known as star join schema and it is optimized for querying large data sets. All the Dimensions in the star schema consist of only one dimension table. Dimension tables are connected to the fact table using a foreign key.
Source: Microsoft
Q7. What is Snowflake Schema? A. Snowflake schema is a data warehouse schema which is an extension of star schema, the dimensions are split and are normalized into more additional tables. As table are normalized, they consume less disk space and easier to implement dimension.
Q8. Can we use Azure Data Studio on the local system instead of Azure VM? A. Yes we can use Azure data studio on the local system and also on Azure VM it depends on what environment you are working in and want to work in.
Q9. Is it possible to make data models on Azure Data studio? A. Azure data studio does not support Model visualization, but we can use other tools like Dbweaver or SQL Server Management Studio (SSMS).
Feedback Received…
Here is some positive feedback from our trainees who attended the session:
Quiz Time (Sample Exam Questions)!
With our Azure Data Engineer Training Program, we cover 150+ sample exam questions to help you prepare for the [DP-203] Certification.
Check out one of the questions and see if you can crack this…
Q. Which SCD type would you use to keep a history of changes in dimension members by adding a new row to the table for each change? A. Type 1 SCD.
B. Type 2 SCD.
C. Type 3 SCD.
Comment with your answer & we will tell you if you are correct or not!
In our Azure Data Engineer training program, we will cover 40Hands-On Labs. If you want to begin your journey towards becoming a Microsoft Certified: Azure Data Engineer Associate by checking our FREE CLASS.