This blog post covers Hands-On Labs that you must perform in order to become a Data Scientist. In these Hands-On labs, you will learn about the most effective Data Science and Machine Learning techniques, and gain practice implementing them and getting them to work for yourself.
This post will help you with your self-paced learning as well as for your team learning. There are 11 Hands-On Labs in this course.
- Data Pre-Processing
- Missing values
- Feature Engineering, encoding, and scaling of data
- Outlier detection & analysis
- Principal Component Analysis (PCA)
- Regression techniques
- Supervised learning
- Ensemble techniques
- Unsupervised learning
- Neural network (Deep learning)
- Natural language processing (NLP)
We will walk you step-by-step into the World of Data Science and Machine Learning. With every hands-on, you will develop new skills and improve your understanding of Data Science & Machine Learning with Python.
Lab 1: Data Pre-Processing
In any Data Science and Machine Learning process, Data Preprocessing is that step in which the data gets converted, or Encoded, to bring it to such a state that now the machine can simply interpret it. In other words, the features of the data can now be simply interpreted by the algorithm.
A feature is an individual measurable characteristic or property of a phenomenon being observed. Features can be:
- Categorical
- Numerical
In this lab, we will learn the following steps to achieve our goal of Data pre-processing.
- Read the default directory name.
- Concatenate directory with files.
- Use concatenated string to read a .csv file using a panda data frame.
- Identify categorical variables.
- Convert those variables into the category.
- Show dimension and basic stat of the data set.
Lab 2: Missing value
In real-time scenarios data is often taken from various sources which are normally not too reliable and that too in diverse formats, more than half our time is expended in dealing with data quality issues when working on Data Science problems.
It is very much expected to have missing values in your dataset. It may have taken place during data collection, or maybe due to some data validation rule, but regardless missing values must be taken into study.
To eliminate and estimate missing data, we will learn the following methods:
- Find the column-wise number of missing values.
- Convert into percentage term.
- Print missing value count.
- Draw the graph showing the missing value count.
- Try out various libraries and packages.
- Identify columns automatically with missing value percentage greater than 30% and Drop those columns.
- Impute missing values by mean/median/most frequent technique.
- Do not impute the missing value of categorical variables.

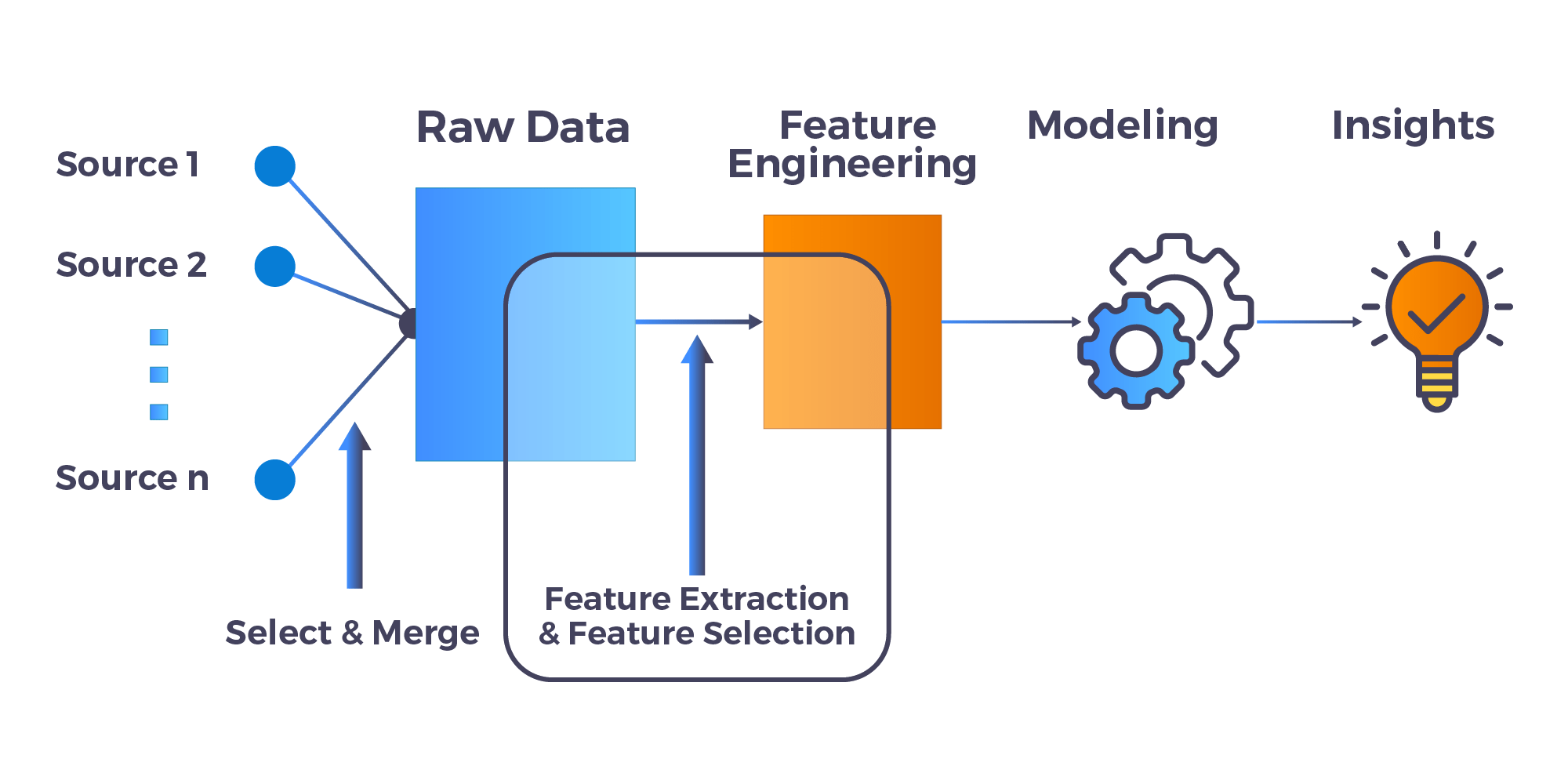
Lab 3: Feature Engineering, Encoding, And Scaling Of Data
Feature Engineering is mostly performing transformations on the data such that it can be simply accepted as input for data science and machine learning algorithms while still keeping its original meaning.
Feature Encoding is the process of Conversion of a categorical variable to numerical features. There are many encoding techniques used for feature engineering:
- Label Encoding
- Ordinal encoding
- Frequency encoding
- Binary encoding
- One hot encoding
- Target Mean encoding
In this lab, we will learn the following techniques:
- Create additional columns based on existing columns
- Encode categorical variables using
- Ordinal encoder
- target encoding
- Scale numeric columns of the data frame
Lab 4: Outlier Detection And Analysis
Data Science algorithms are very sensitive to the distribution and range of data points. Data outliers can betray the training process resulting in longer training times and less precise models. Outliers are specifying as samples that are significantly different from the remaining data. Those are points that lie outside the total pattern of the distribution. Statistical measures such as variance, mean, and correlation are very inclined to outliers. The following ways to identify outliers:
- Extreme Value Analysis
- Z-score method
- Visualizing the data
- K Means clustering-based approach
In this lab, we will learn the following method:
- Visualize the outlier of each column.
- Outlier detection with various methods.

Lab 5: Principal Component Analysis (PCA)
In data science, Principal Component Analysis (PCA) comes under the Unsupervised Learning Algorithm. PCA implements the Dimensionality Reduction technique. The aim of PCA is the elimination of unrelated features while developing a model. PCA pulls the most dependent features contributing to the output.
The main objective of PCA is given below:
- Elimination of irrelevant features.
- Increase the prediction accuracy of models.
- Improve the reduction of storage and computation cost.
- Advance the knowledge of data and the model.
In this lab, we will learn the following method:
- Split the dataset into train/test
- Scale data and apply PCA.

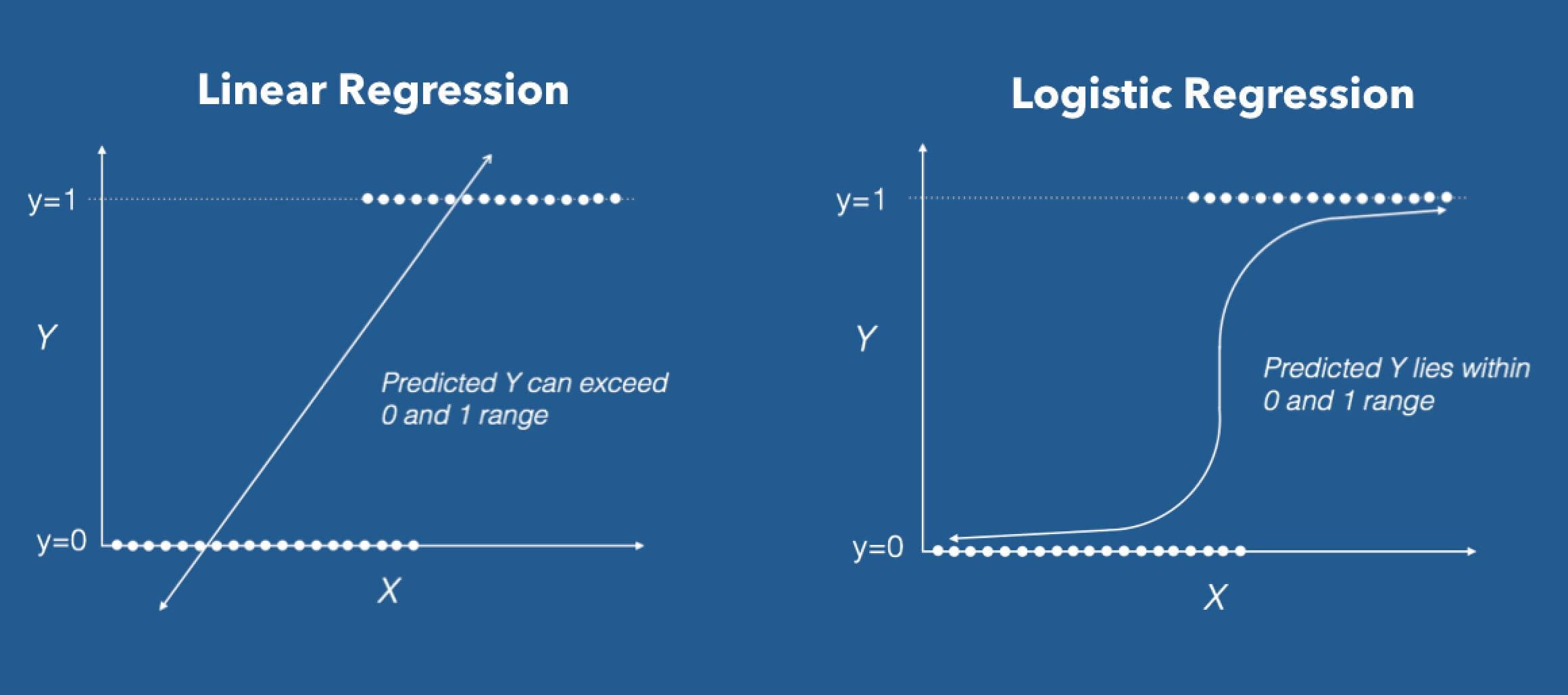
Lab 6: Regression Techniques
To implement a relationship between the independent and dependent variables of a given dataset we use Regression. It is a statistical tool. However, when we used the Linear Regression algorithm, we consider a linear relationship between one independent and one dependent variable. when the dependent variable(target) is categorical we used Logistic Regression.
In this lab, we will learn the following regression techniques:
- Linear regression
- Logistic regression
- Regularization
Lab 7: Supervised Learning
In supervised learning, the training set we feed to the algorithm includes the desired solutions, called labels. In Data Science and Machine Learning, a typical supervised learning task is classification. The spam filter is a good example of Supervised Learning. Here are some of the most important supervised learning algorithms:
- k-Nearest Neighbors
- Linear Regression
- Logistic Regression
- Support Vector Machines (SVMs)
- Decision Trees and Random Forests
In this lab, we will learn the following supervised learning techniques:
- Naïve Bayes
- KNN
- Support Vector Machine (SVM)

Lab 8: Ensembling Techniques
In ensemble methods, we create a number of Data Science and Machine Learning algorithms like KNN, Decision Trees, Logistic Regression, SVM, etc, and mix these algorithms together to find better predictions.
Decision Trees are versatile ML algorithms that can perform both regression and classification tasks, and even multioutput tasks. an ensemble of Decision Trees is called a Random Forest.
In this lab, we will learn the following ensembling techniques:
- Decision Trees
- Random forest

Lab 9: Unsupervised Learning
In unsupervised learning, the training data is unlabeled. The system tries to learn without a teacher. Here are some of the most important unsupervised clustering learning algorithms are:
- K-Means
- DBSCAN
- Hierarchical Cluster Analysis (HCA)
In this lab, we will learn the following unsupervised techniques:
- K-means clustering

Lab 10: Neural network (Deep Learning)
Artificial Neural Networks are at the very core of Deep Learning. They are powerful, versatile, and scalable, making them ideal to tackle large and highly complex Machine Learning tasks powering speech recognition services (e.g., Apple’s Siri), classifying billions of images (e.g., Google Images), recommending the best videos to watch (e.g., YouTube).
In this lab, we will learn the following deep learning techniques:
- Single-layer neural network
- Multilayer neural network
- Convolutional neural network (CNN)

Lab 11: Natural language processing (NLP)
Natural language processing (NLP) refers to the branch of computer science and more specifically, the branch of artificial intelligence or AI concerned with giving computers the ability to understand the text and spoken words in much the same way human beings can.
In this lab, we will learn the following Natural language processing (NLP) techniques:
- Natural language processing techniques
- Text retrieval, cleaning, tokenization, lemmatization, word embedding, and POS tagging.
- TF-IDF, pad sequences, and word cloud
- Sentiment analysis

Note: Every lab will include real-time case studies and datasets.
Next Task For You
Begin your journey towards Introduction To Data Science and Machine Learning by joining our FREE Informative Class on Introduction To Data Science and Machine Learning by clicking on the below image.

The post Hands-On Data Science And Machine Learning Labs With Python appeared first on Cloud Training Program.