
In this blog, we will look at what steps are taken into consideration while data preparation with Azure Databricks for machine learning.
Azure Databricks
Azure Databricks is a data analytics platform optimized for the Microsoft Azure cloud services platform. Azure Databricks offers three environments for developing data-intensive applications: Databricks SQL, Databricks Data Science & Engineering, and Databricks Machine Learning.
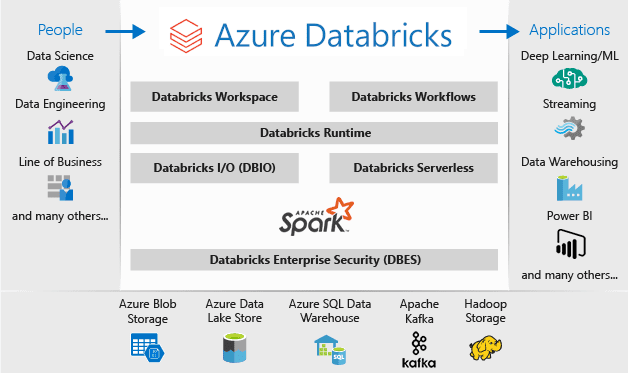
Databricks Machine Learning is an integrated end-to-end machine learning environment incorporating managed services for experiment tracking, model training, feature development and management, and feature and model serving.
Machine Learning
Machine learning is a data science technique used to extract patterns from data allowing computers to identify related data, forecast future outcomes, behaviors, and trends.
The result of training a machine learning algorithm is that the algorithm has learned the rules to map the input data to answers.

In machine learning, you train the algorithm with data and answers, also known as labels, and the algorithm learns the rules to map the data to their respective labels.
Databricks Environment Setup
Before we get into the four prominent data preparation with Azure Databricks steps for machine learning, let’s set up our data bricks environment.
Step 1: Create your Azure Free Trial Account if you do not have one or log in with your existing credentials.
Step 2: In the Azure portal, create a new Azure Databricks resource, specifying the following settings as shown in the image. Validate the details and create the workspace.
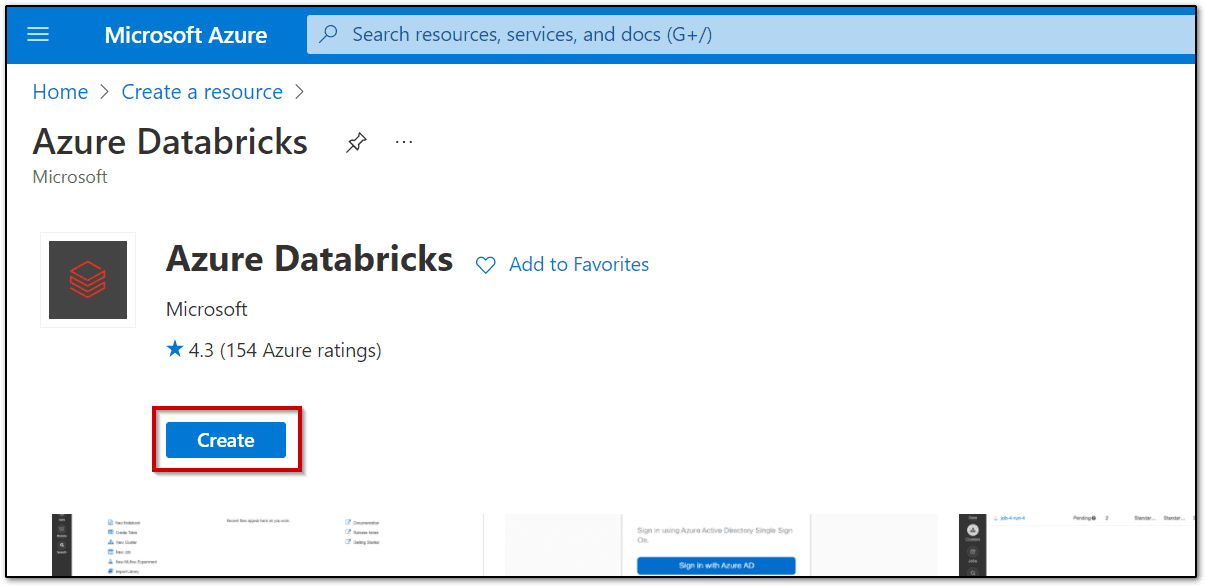

Step 3: Once the resource workspace is created, launch the Databricks workspace.
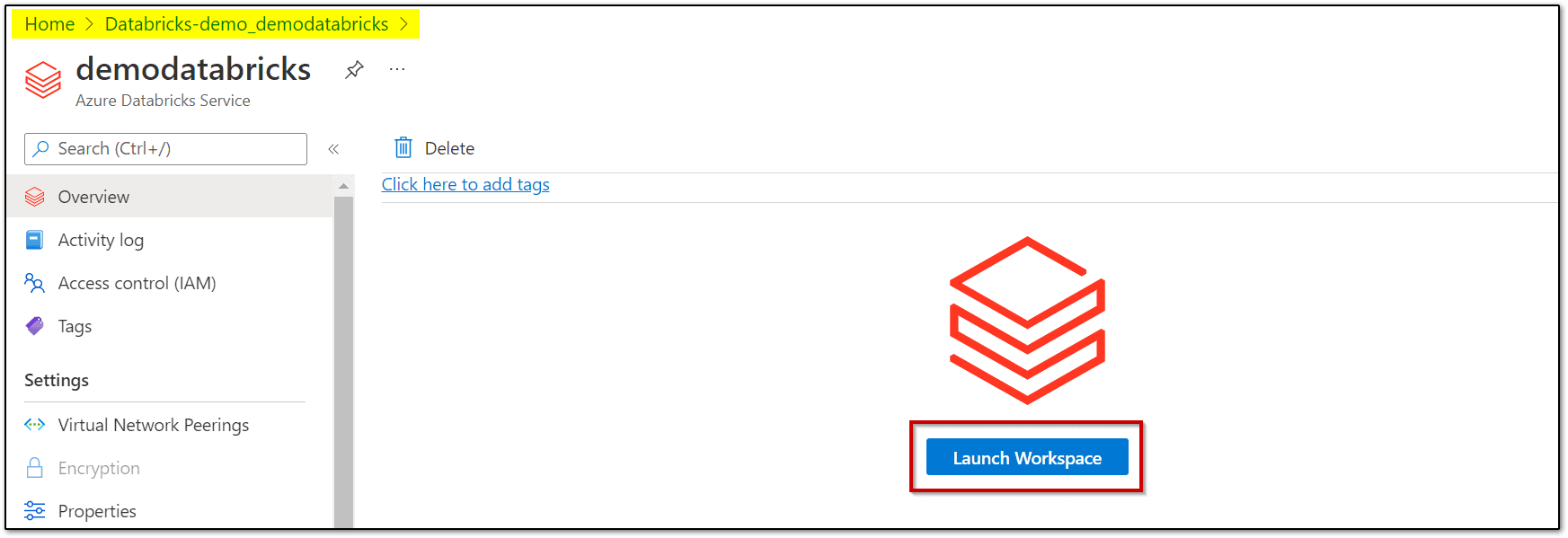
Step 4: In the left-hand menu of your Databricks workspace, select Compute, and then select + Create Cluster to add a new cluster.

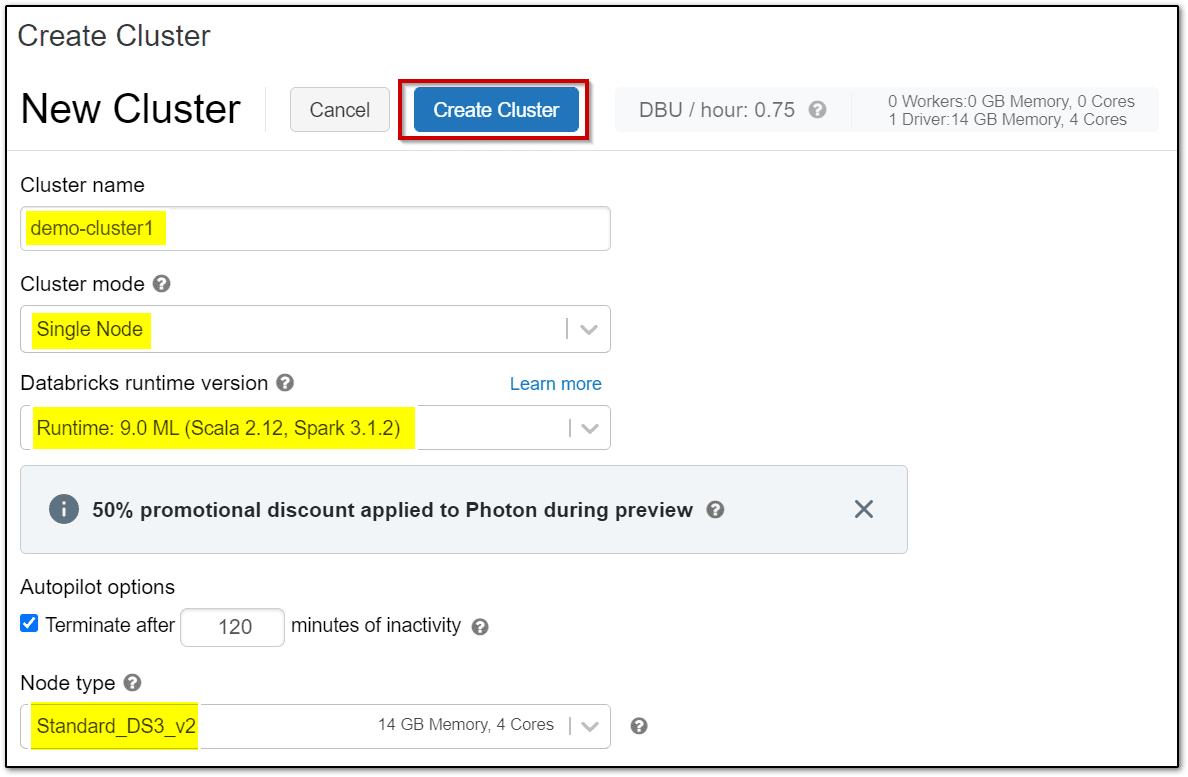
Step 5: Confirm that the cluster is created and running.
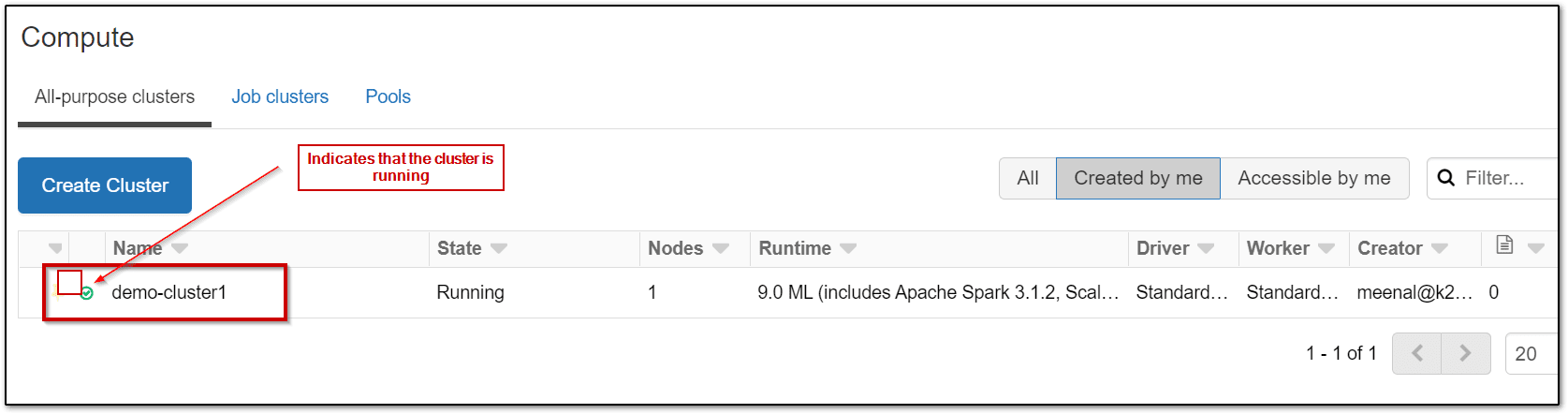
Step 6: Load the dataset which is to be used for the experiment in the Azure Databricks workspace for machine learning. Here we are using nyc-train dataset. Download the dataset on your laptop.
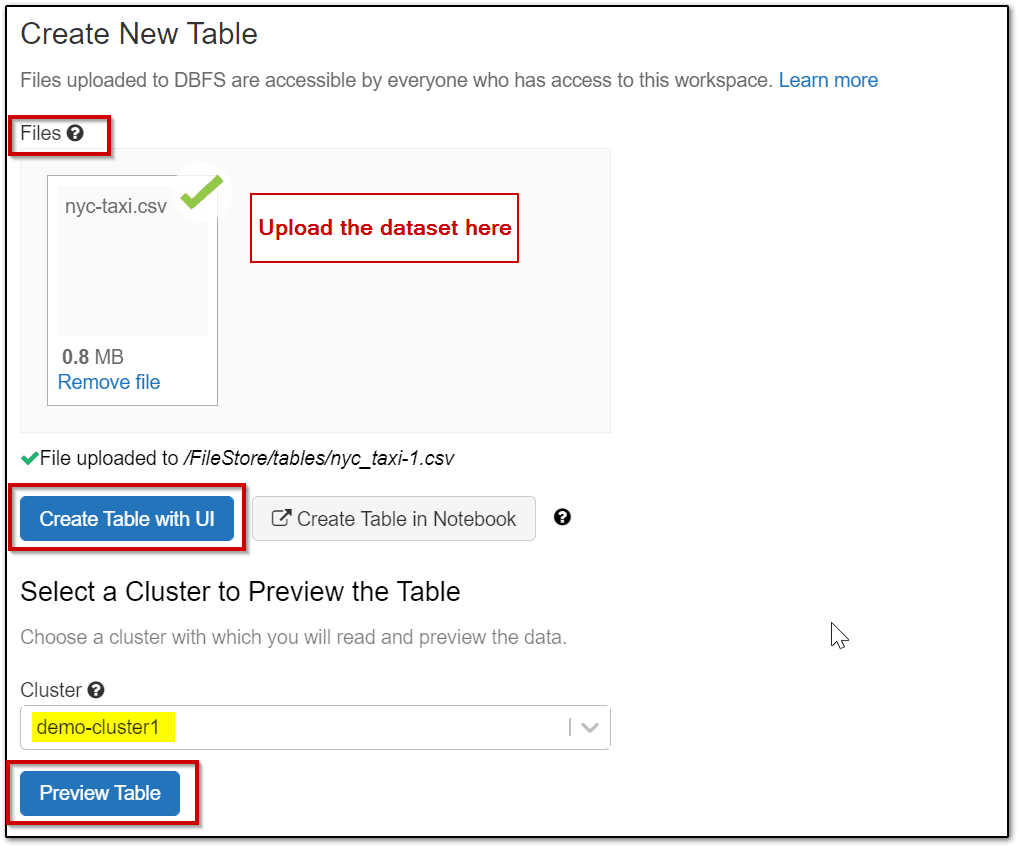
- On the Data page in the Databricks Workspace, select the option to Create Table.
- In the Files area, select browse and then browse to the nyc-taxi.csv file you downloaded.
- After the file is uploaded to the workspace, select Create Table with UI. Then select your cluster and select Preview Table.
Step 7: Check & verify the attribute fields and click on create a table.

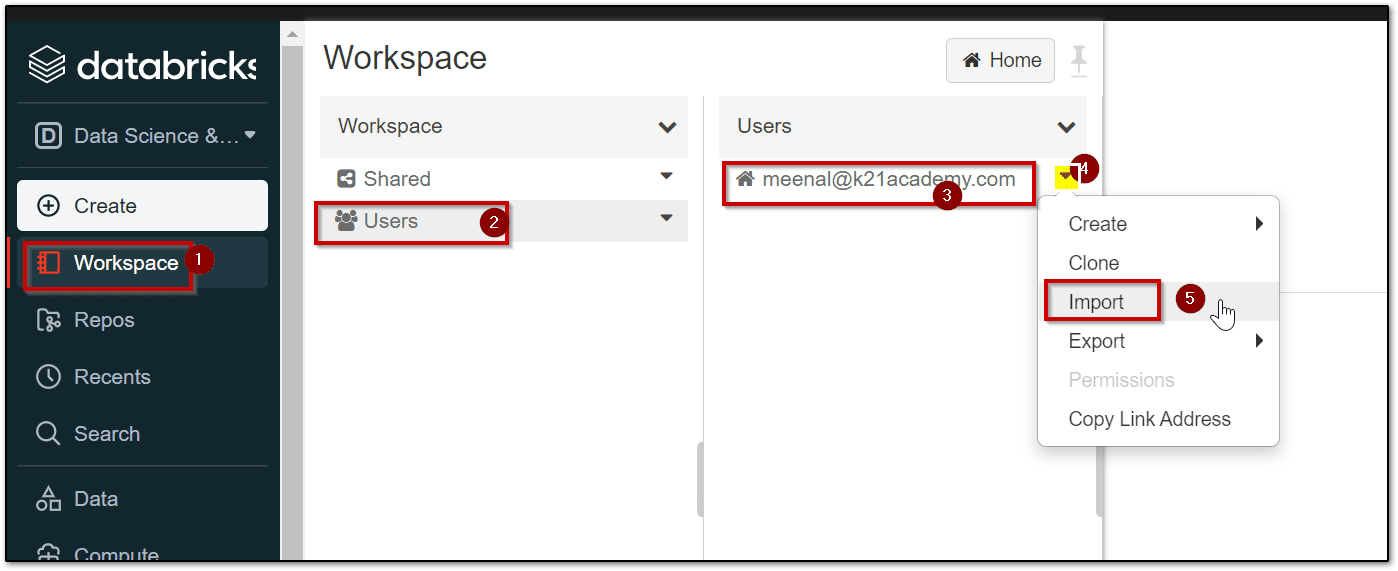
Step 8: In the Azure Databricks Workspace, using the command bar on the left, select Workspace -> select Users -> ☗ your_user_name. In the blade that appears, select the downwards pointing chevron (v) next to your name, and select Import.
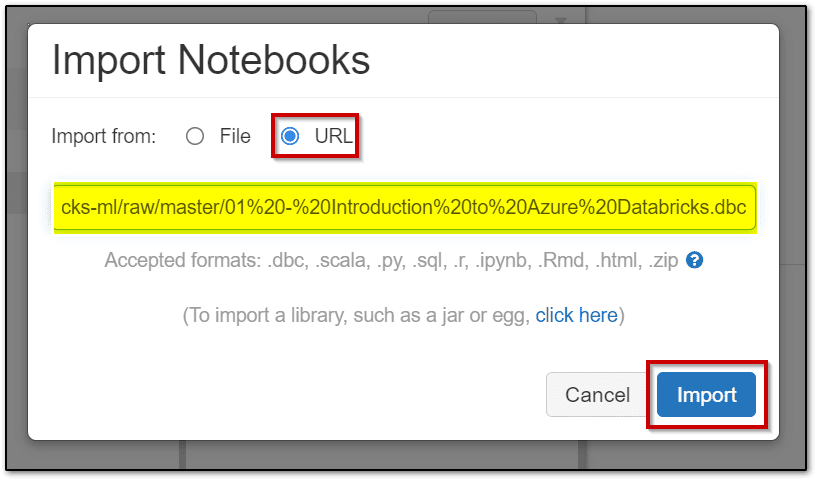
Step 9: On the Import Notebooks dialog, import the notebook archive.
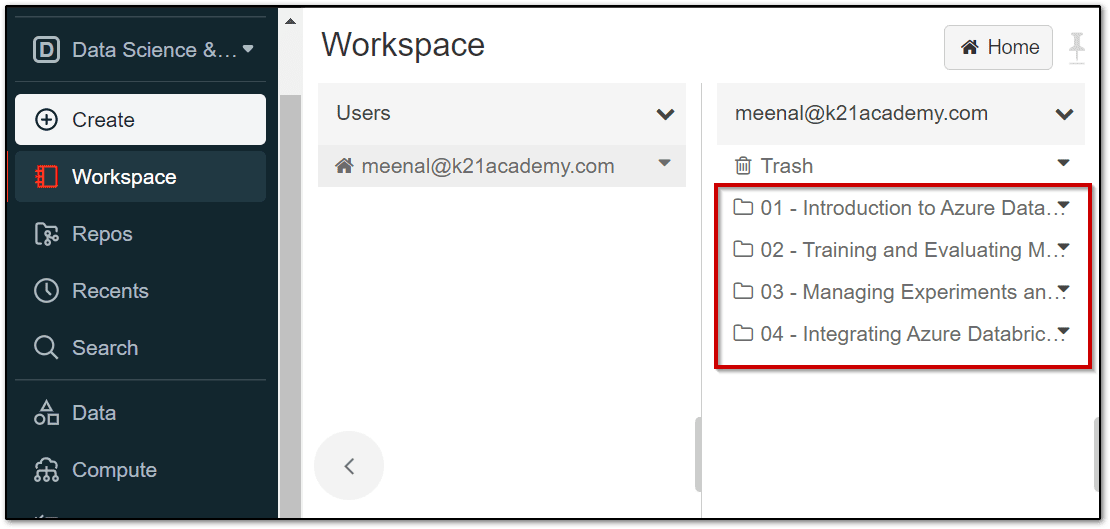
Step 10: Once the notebooks are imported, open the 2nd Notebook and attach your compute cluster.

Now you are all set to perform the data preparation with Azure Databricks steps in the notebook
Data Preparation with Azure Databricks Steps
Big Data has become part of the lexicon of organizations worldwide, as more and more organizations look to leverage data to drive more informed business decisions. With this evolution in business decision-making, the amount of raw data collected, along with the number and diversity of data sources, is growing at an astounding rate.
Now let’s look at the four main data preparation steps:
- Data Cleaning
- Feature Engineering
- Data Scaling
- Data Encoding
1.) Perform Data Cleaning
Raw data is often noisy and unreliable and may contain missing values and outliers. Using such data for Machine Learning can produce misleading results. Thus, data cleaning of the raw data is one of the most important steps in preparing data for Machine Learning. As a Machine Learning algorithm learns the rules from data, having clean and consistent data is an important factor in influencing the predictive abilities of the underlying algorithms.
Data cleaning deals with issues in the data quality such as errors, missing values, and outliers and there are several techniques in dealing with data quality issues. Common data cleaning strategies include:
- Imputation of null values
- converting data types
- Duplicate Records
- Outliers
A very common option to work with missing data is to impute the missing values with the best guess for their value.

2.) Perform Feature Engineering
Machine learning models are as strong as the data they are trained on. Often it is important to derive features from existing raw data that better represent the nature of the data and thus help improve the predictive power of the machine learning algorithms. This process of generating new predictive features from existing raw data is commonly referred to as feature engineering.
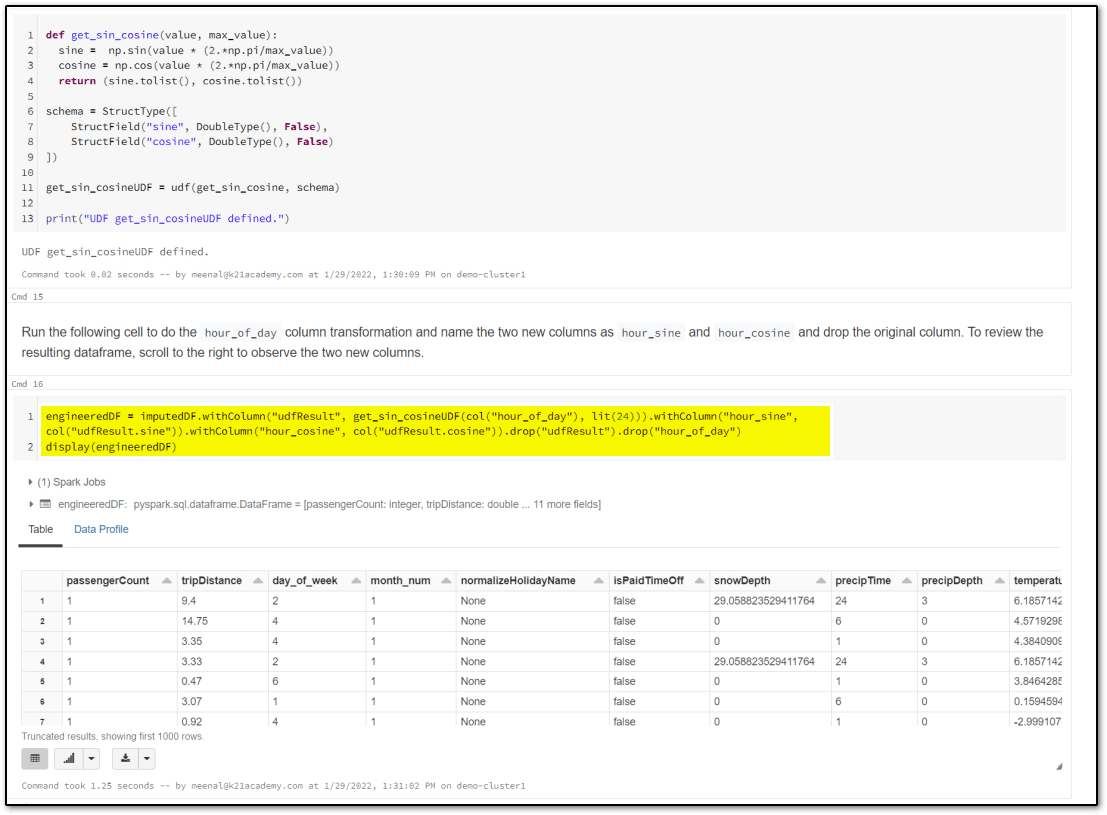
3.) Perform Data Scaling
Scaling numerical features is an important part of preprocessing data for machine learning. Typically the range of values each input feature takes varies greatly between features. There are many machine learning algorithms that are sensitive to the magnitude of the input features and thus without feature scaling, higher weights might get assigned to features with higher magnitudes irrespective of the importance of the feature on the predicted output.
There are two common approaches to scaling numerical features:
- Normalization: mathematically rescales the data into the range [0, 1].
- Standardization: rescales the data to have mean = 0 and standard deviation = 1.
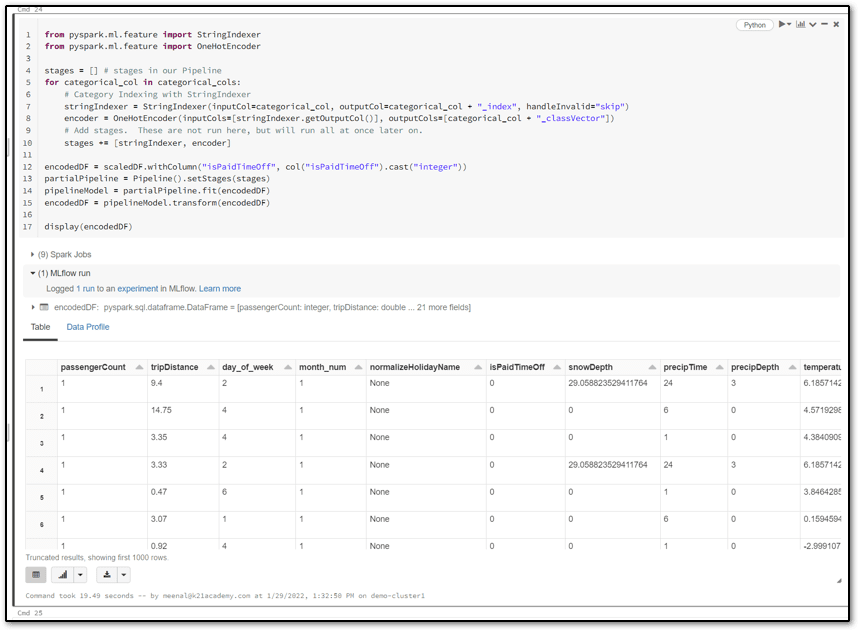
4.) Perform Data Encoding
A common type of data that is prevalent in machine learning is called categorical data. Categorical data implies discrete or a limited set of values. Two common approaches for encoding categorical data are:
- Ordinal encoding: converts categorical data into integer codes ranging from 0 to (number of categories – 1)
- One-hot encoding: often the recommended approach, and it involves transforming each categorical value into n (= number of categories) binary values, with one of the 1, and all others 0.
One-hot encoding is often preferred over ordinal encoding because it encodes each category item with equal weight.
Hope this blog helps you in understanding the concepts & steps of data preparation with Azure Databricks for Machine Learning.
- [DP-100] Microsoft Certified Azure Data Scientist Associate: Everything you must know
- Microsoft Azure Data Scientist DP-100 FAQ
- MLOps on Azure
- Machine Learning Service Workflow
- Azure ML Model in Production
- Datasets & Datastores in Azure
Next Task For You
To know more about the course, AI, ML, Data Science for beginners, why you should learn, Job opportunities, and what to study Including Hands-On labs you must perform to clear [DP-100] Microsoft Azure Data Scientist Associate Certification register for our FREE CLASS.

The post Prepare Data for Machine Learning with Azure Databricks appeared first on Cloud Training Program.