In this blog, we are covering Structured Streaming, Events Hubs, Streaming With Event Hubs
Topics we’ll cover:
- What is structured streaming
- What is Event Hub
- Component of Azure Event Hubs
- What is Event Hub
- Streaming With Event Hubs
What Is Structured Streaming
Apache Spark Structured Streaming is a fast, scalable, and fault-tolerant stream processing API. You can use it to perform analytics on your streaming data in near real-time.
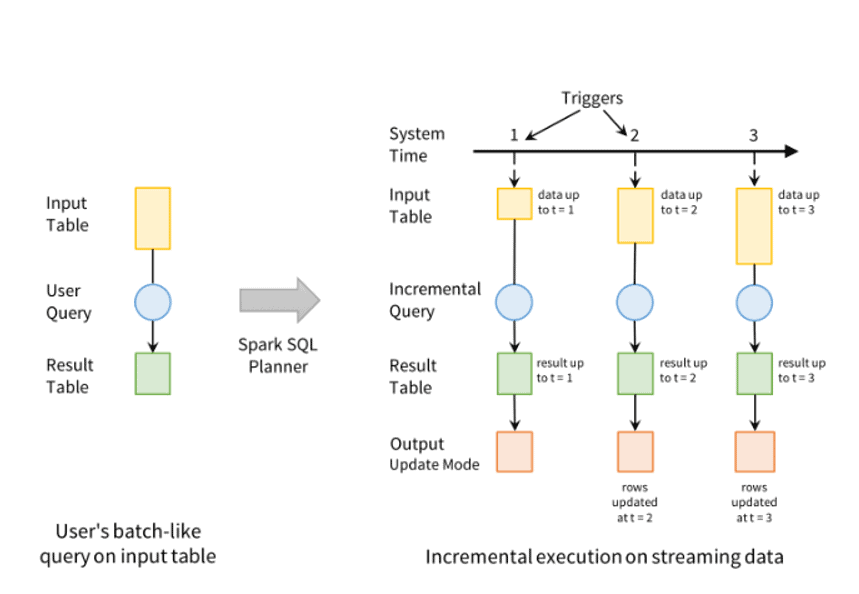
Source: Databricks
With Structured Streaming, you can use SQL queries to process streaming data in the same way that you would process static data. The API continuously increments and updates the final data.
What Is Event Hub
Azure Event Hubs is a scalable real-time data ingestion service that processes millions of data in a matter of seconds. It can receive large amounts of data from multiple sources and stream the prepared data to Azure Data Lake or Azure Blob storage.
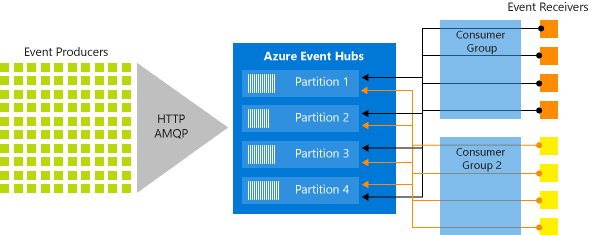
Source: Microsoft
Azure Event Hubs can be integrated with Spark Structured Streaming to perform the processing of messages in near real-time. You can query and analyze the processed data as it comes by using a Structured Streaming query and Spark SQL.
Check out our related blog here: What is Azure Event Hubs & How It Works?
Components of Azure Events Hubs
- Event producers: Any object that sends an event to an event hub.
- Partitions: we can only read a particular subset, or segment, of the message stream.
- Consumer groups: The data can be used by different consumers according to their own requirements. Some consumers want to use it carefully only once, some consumers used historical data again and again.
- Throughput units: Throughput units are the foundation of how you can scale the traffic coming in and going out of azure Event Hubs. Think of throughput units like water pipes, if you required more water to flow through, you required more water pipes.
- Event receivers: Any object (applications) that read event data from an Azure Event Hub is a receiver.
What Is Event Grid
Azure Event Grid is used to build applications very simply and rapidly with event-based architectures. Event Grid has an inbuilt support structure for events coming from the different Azure services, like blobs storage and resource groups. We will use filters to route particular events to different endpoints, multicast to many endpoints, and make sure your events are surely delivered.
- Event sources – where the event took place.
- Event Handlers – the service or app reacting to the event.
Streaming With Event Hubs
1.) Create Databricks Workspace
1. If you do not currently have your Azure Databricks workspace open: in the Azure portal, navigate to your deployed Azure Databricks workspace and select Launch Workspace.
2. In the left pane, select Compute. If you have an existing cluster, ensure that it is running (start it if necessary). If you don’t have an existing cluster, create a single-node cluster that uses the latest runtime and Scala 2.12 or later.
2.) Clone Databricks Archive
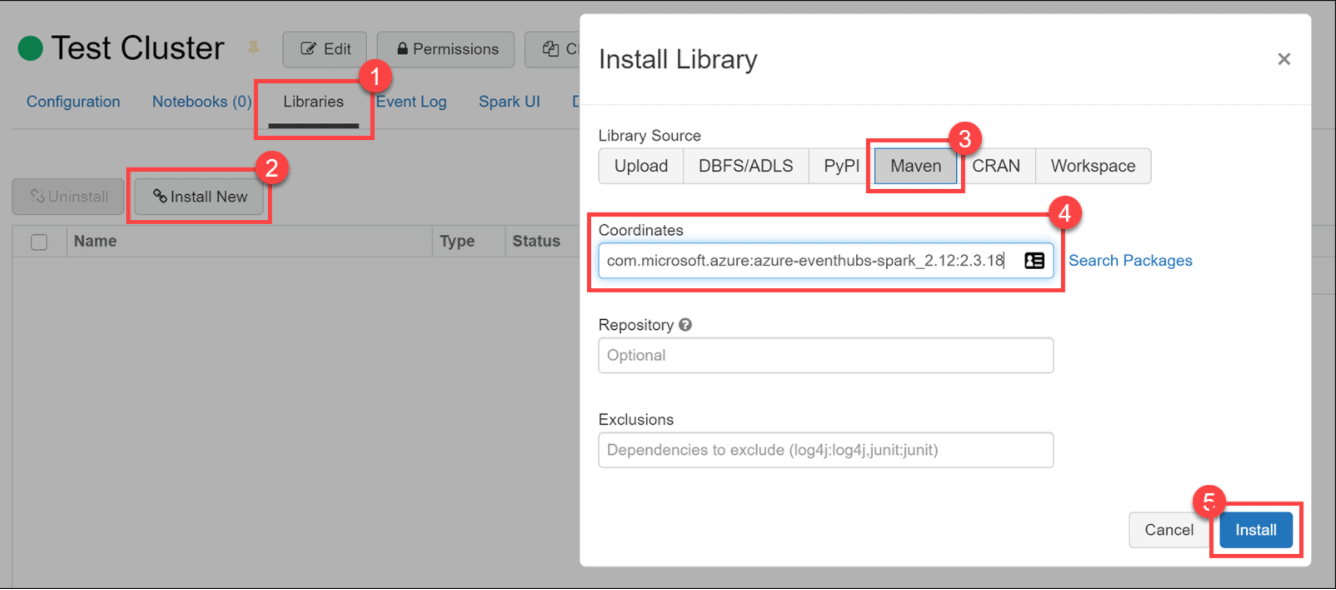
1. Select the Libraries tab, then select Install New. In the Install Library dialog, select Maven under Library Source. Under Coordinates, paste com.microsoft.azure:azure-eventhubs-spark_2.12:2.3.18 , then select Install the library.
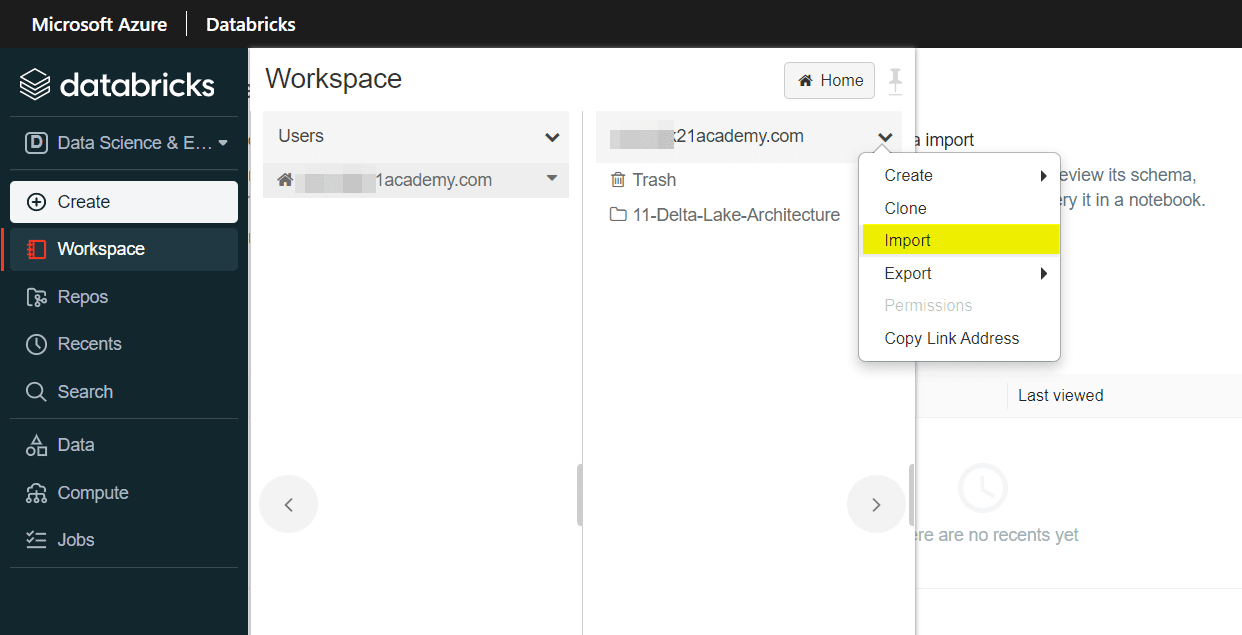
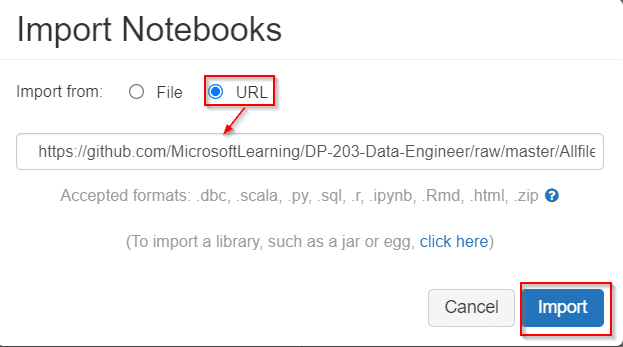
2. When your cluster is running, in the left pane, select Workspace > Users, and select your username (the entry with the house icon).In the Import Notebooks dialog box, select the URL and paste in the following URL:
https://github.com/MicrosoftLearning/DP-203-Data-Engineer/raw/master/Allfiles/microsoft-learning-paths-databricks-notebooks/data-engineering/DBC/10-Structured-Streaming.dbc
3.) Creating Event Hubs
1. Run the following two cells to install the azure-event hub Python library and configure our “classroom”
# This library allows the Python kernel to stream content to an Event Hub: %pip install azure-eventhub %run "./Includes/Classroom-Setup"
2. In order to reach Event Hubs, you will need to insert the connection string-primary key you acquired at the end of the Getting Started notebook in this module. You acquired this from the Azure Portal and copied it into Notepad.exe or another text editor.
event_hub_connection_string = "REPLACE-WITH-YOUR-EVENT-HUBS-CONNECTION-STRING" # Paste your Event Hubs connection string in the quotes to the left

4.) Reading and Writing In Azure Event Hubs
1. Name your event hub.
%python
event_hub_name = "databricks-demo-eventhub"
connection_string = event_hub_connection_string + ";EntityPath=" + event_hub_name
print("Consumer Connection String: {}".format(connection_string))
2. Write Stream to Event Hub to Produce Stream.
%python
# For 2.3.15 version and above, the configuration dictionary requires that connection string be encrypted.
ehWriteConf = {
'eventhubs.connectionString' : sc._jvm.org.apache.spark.eventhubs.EventHubsUtils.encrypt(connection_string)
}
checkpointPath = userhome + "/event-hub/write-checkpoint"
dbutils.fs.rm(checkpointPath,True)
(activityStreamDF
.writeStream
.format("eventhubs")
.options(**ehWriteConf)
.option("checkpointLocation", checkpointPath)
.start())
3. Now we READ Stream using Event Hubs.
%python
from pyspark.sql.functions import col
spark.conf.set("spark.sql.shuffle.partitions", sc.defaultParallelism)
eventStreamDF = (spark.readStream
.format("eventhubs")
.options(**eventHubsConf)
.load()
)
eventStreamDF.printSchema()
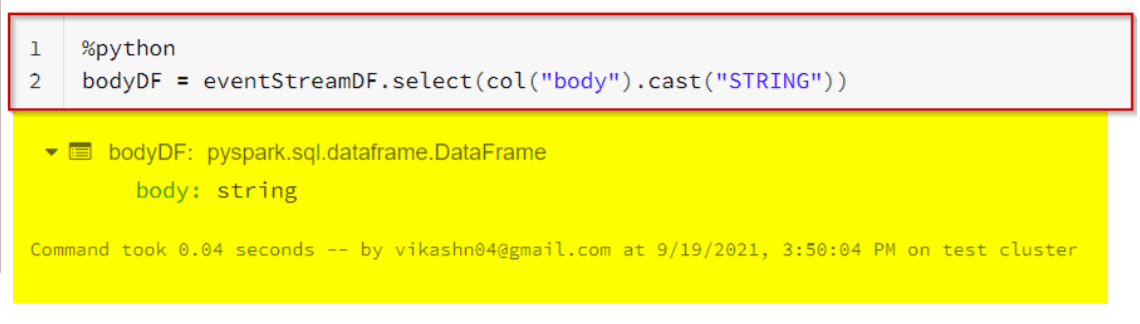
 4. Most of the fields in this response are metadata describing the state of the Event Hubs stream. We are specifically interested in the body field, which contains our JSON payload. Noting that it’s encoded as binary, as we select it, we’ll cast it to a string.
4. Most of the fields in this response are metadata describing the state of the Event Hubs stream. We are specifically interested in the body field, which contains our JSON payload. Noting that it’s encoded as binary, as we select it, we’ll cast it to a string.
%python
bodyDF = eventStreamDF.select(col("body").cast("STRING"))
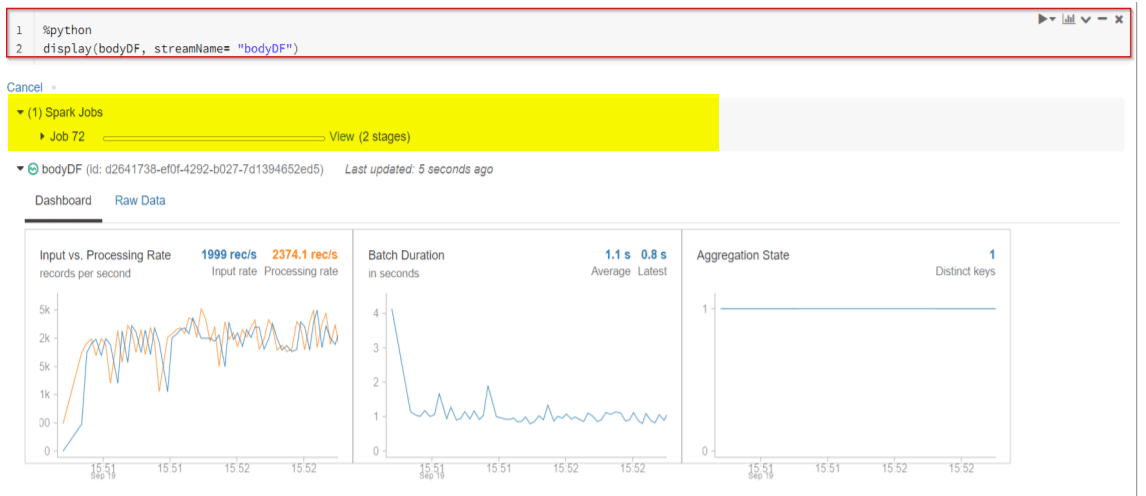
5. Each line of the streaming data becomes a row in the DataFrame once an action such as write stream is invoked. Notice that nothing happens until you engage an action, i.e. a display() or writeStream.
%python display(bodyDF, streamName= "bodyDF")
Conclusion
Structured Streaming in Apache Spark is the best framework for writing your streaming ETL pipelines, and Databricks makes it easy to run them in production at scale. The Spark SQL engine performs the computation incrementally and continuously updates the result as streaming data arrive.
Related/References
- Microsoft Certified Azure Data Engineer Associate | DP 203 | Step By Step Activity Guides (Hands-On Labs)
- Exam DP-203: Data Engineering on Microsoft Azure
- Microsoft Azure Data Engineer Associate [DP-203] Interview Questions
- Azure Data Lake For Beginners: All you Need To Know
- Batch Processing Vs Stream Processing: All you Need To Know
- Reading and Writing Data In DataBricks
Next Task For You
In our Azure Data Engineer training program, we will cover all the exam objectives, 27 Hands-On Labs, and practice tests. If you want to begin your journey towards becoming a Microsoft Certified: Azure Data Engineer Associate check our FREE CLASS.

The post Structured Streaming With Azure Event Hubs appeared first on Cloud Training Program.