
In this blog, we are going to cover an Introduction To Hive, the Architecture of Hive, features of Hive, and its Limitation on Big data.
Topics we’ll cover :
Introduction To Hive
Apache Hive is often referred to as ETL and Data warehousing infrastructure tool which is developed on the top of Hadoop file distributed system. Hive is useful for performing operations on Adhoc-queries, Data Encapsulation, and Analysis of huge datasets stored in file systems like HDFS (Hadoop Distributed Framework System).
Hive was developed by Facebook to query their huge amount of data each day (around 20TB) and later it is took up by the Apache software foundation.
Architecture Of Hive
The Hive consists of the following components :
- Hive Client
- Hive Services
- Hive Storage and Computing
![hive architecture]()

1. Hive Client
Hive Provides supports for the applications written in programming languages like python, java, etc. by using the JDFC, ODBC, and drivers for performing any queries on the drive. And hive client is categorized into three parts.
Thrift Clients: A Hive server is based on the apache thrift, so it can serve the request from a thrift client.
ODBC Client: It is the client application that supports ODBC protocol.
JDBC Client: It is a java application that supports JDBC protocol. Hive allows these applications to connect to it by using the JDBC drivers.
2. Hive Services
Hive CLI: We can execute the hive queries in the Hive CLI (Command Line Interface) is a shell.
Hive Web User Interface: The Hive Web UI is just an alternative to Hive CLI. It provides a web-based GUI for executing Hive queries and commands.
Hive meta store: It is a central repository that stores all the structure information of various tables and partitions in the warehouse. It also includes metadata of column and its type information, the serializers and deserializers which is used to read and write data, and the corresponding HDFS files where the data is stored.
Hive Server: It is referred to as Apache Thrift Server. It accepts the request from different clients and provides it to Hive Driver.
Hive Driver: It receives queries from different sources like web UI, CLI, Thrift, and JDBC/ODBC driver. It transfers the queries to the compiler.
Hive Compiler: The purpose of the compiler is to parse the query and perform semantic analysis on the different query blocks and expressions. It converts HiveQL statements into MapReduce jobs.
Hive Execution Engine: Optimizer generates the logical plan in the form of DAG of map-reduce tasks and HDFS tasks. In the end, the execution engine executes the incoming tasks in the order of their dependencies.
3. Hive Storage and Computing
Hive services such as Meta store, File system, and Job Client, in turn, communicate with Hive storage and performs the following actions
- Metadata information of tables created in Hive is stored in Hive “Meta storage database”.
- Query results and data loaded in the tables are going to be stored in the Hadoop cluster on HDFS.
Hive Data Model
Hive organizes the data into the different data models
- Tables
- Partitions
- Buckets
![]()

1. Tables
These tables are similar to the RDBMS database tables. We can perform filters, joins, projects, and union of the hive tables. All the data of a table is stored as a directory in HDFS.
2. Partitions
Hive organizes tables into partitions based on partition keys for grouping similar data together.
3. Buckets
The partitions are further categorized into buckets based on the hash function of a column in the table. These buckets are stored as a file in the partition directory.
Features of Hive![hive features]()

Open-Source: It is an open-source tool so we can use it free of cost.
Query large datasets: It is used to manage the datasets that are stored in the Hadoop Distributed File System.
File Formats: It supports various types of file formats such as textfile, ORC, Parquet, LZO Compression, etc.
Hive-Query Language: This language is similar to SQL. Only the basic knowledge of SQL is enough to work with Hive such as tables, rows, columns, and schema, etc.
Fast: Hive is a Fast, scalable, extensible tool and uses familiar concepts.
Table Structure: Hive as data warehouse designed for managing and querying only structured data that is stored in tables that is similar to RDBMS Tables.
Ad-hoc Queries: Hive allows us to run ad-hoc queries which are the commands or queries whose value depends on some variable for the data analysis.
ETL Support: ETL Functionalities such as Extraction, Transformation, and Loading data into tables coupled with joins, partitions, etc.
Limitation of Hive
- It does not offer real-time queries for row-level updates.
- The latency in the apache hive query is very high.
- Hive only supported online analytical processing (OLAP) and doesn’t support online transaction processing (OLTP).
- Hive Query Language doesn’t support the transaction processing feature.
Next Task For You
Interested in increasing your knowledge of the Big Data landscape? This course is for those new to data science and interested in understanding why the Big Data Era has come to be. If you want to begin your journey towards becoming a Big Data Engineer then register at our FREE CLASS.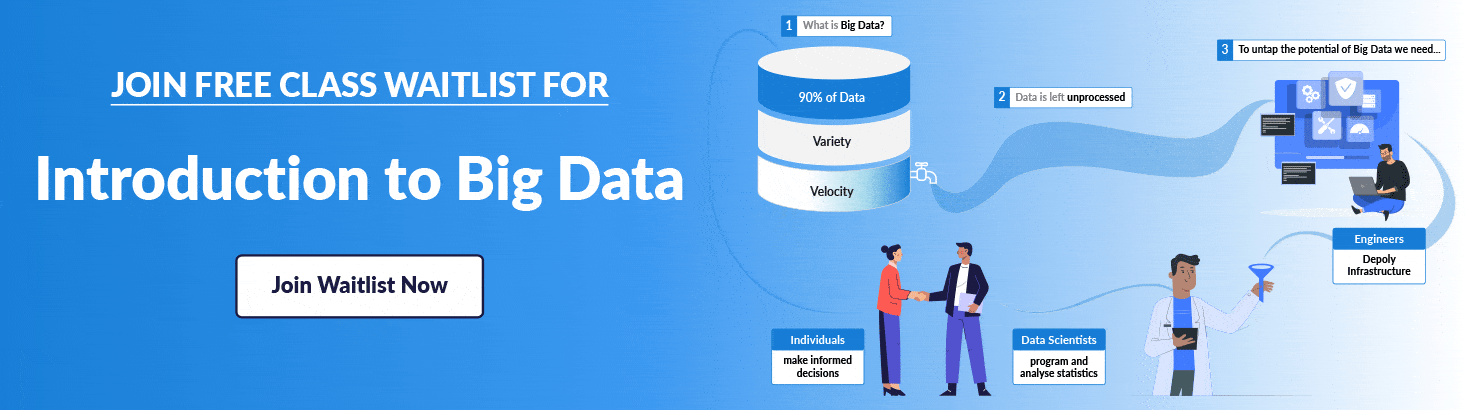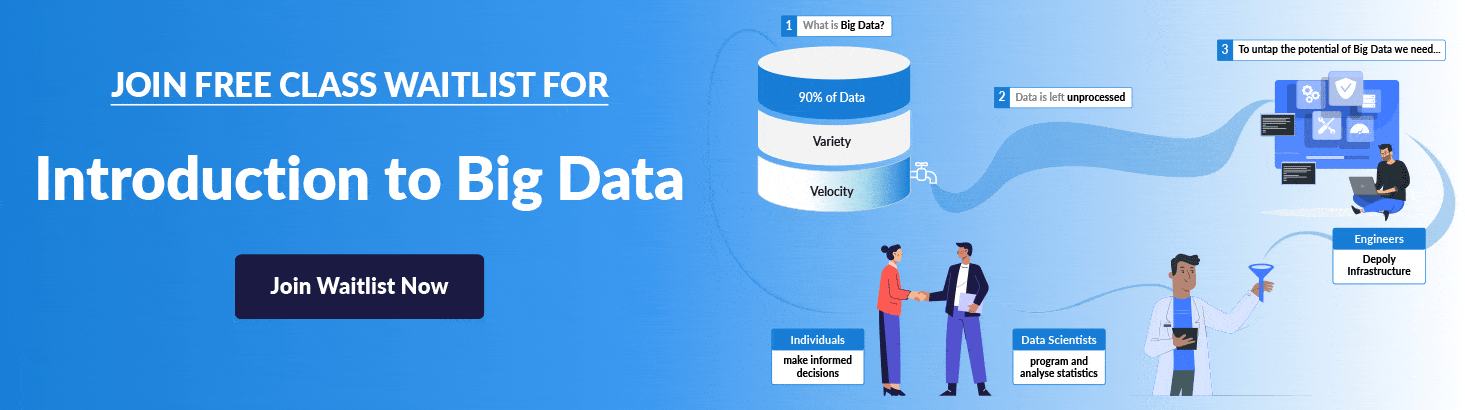
The post Introduction To Hive | Its Features & Limitations appeared first on Cloud Training Program.