
In this blog, we are going to discuss the assorted ways in which to envision the performance of our machine learning model and why to use one in situ of the other. we are going to discuss terms like:
- Confusion matrix
- Accuracy
- Precision
- Recall/Sensitivity/True Positive Rate
- Specificity
- False Positive Rate
- F1 score
- ROC (Receiver Operating Characteristics) curve
- AUC
- RMSE
- R-Squared (R²)
The goal of a Machine Learning Model is to find out patterns that generalize well on unseen information rather than simply memorizing the information that it had been trained on. once your model is prepared, you’d use it to predict the solution on the analysis or take a look at the data set then compare the anticipated target to the particular answer (ground truth). this can be a typical approach that’s followed to judge model performance. However, this comparison between foreseen and actual values is performed a supported a variety of various metrics. the selection of actual metrics depends on the ML drawback at hand.
1. Confusion Matrix
A key conception that we want to understand before having the ability to clarify the performance metrics is the confusion matrix.
Definition: A confusion matrix may be a table that’s usually accustomed to describe the performance of a classification model (or “classifier”) on a group of taking a look at data that truth values are well-known.
A confusion matrix can appear as if this:

we will largely discuss things in terms of a binary classification drawback wherever let’s say we’ll have to be compelled to realize if a picture is of a cat or a dog. Or a patient has cancer (positive) or is found healthy (negative). Some common terms to be clear with are:
- True positives (TP): Predicted positive and are actually positive.
- False positives (FP): Predicted positive and are actually negative.
- True negatives (TN): Predicted negative and are actually negative.
- False negatives (FN): Predicted negative and are actually positive.
Typical metrics for classification issues are Accuracy, Precision, Recall, False positive rate, F1-measure, and these are derived from Confusion Matrix. every metric measure a special side of the predictive model.
2. Accuracy
The most ordinarily used metric to gauge a model and is really not a transparent indicator of the performance. the more serious happens once categories are unbalanced.

Take for example a cancer detection model. the probabilities of really having cancer are terribly low. Let’s say out of a hundred, ninety of the patients don’t have cancer and therefore the remaining ten even have it. we have a tendency to don’t wish to miss on a patient who has cancer however goes unseen (false negative). detective work everybody as not having cancer offers an accuracy of ninetieth straight. The model did nothing here however simply gave cancer-free for all the hundred predictions.
3. Precision
Percentage of positive instances out of the total predicted positive instances. Here divisor is that the model prediction is done as positive from the complete given dataset. Take it on resolve ‘how abundant the model is true once it says it’s right’.

4. Recall/Sensitivity/True Positive Rate(TPR)
Percentage of positive instances out of the total actual positive instances. so divisor (TP + FN) here is the actual number of positive instances gift within the dataset. Take it on resolve ‘how much further right ones, the model lost once it showed the correct ones’.

5. Specificity
Percentage of negative instances out of the total actual negative instances. so divisor (TN + FP) here is the actual number of negative instances of the gift within the dataset. it’s just like recall however the shift is on the negative instances. Like sorting out what percentage of healthy patients weren’t having cancer and were told they don’t have cancer. reasonably a live to visualize however separate the categories are.
![]() 6. False Positive Rate (FPR)
6. False Positive Rate (FPR)
 6. False Positive Rate (FPR)
6. False Positive Rate (FPR)This term offers you the number of false positives (0s predicted as 1s) divided by the entire number of negatives. you’ll be able to see that the formula for False Positive Rate (FPR) is nothing but (1 — Specificity)
7. F1 score
It is the mean value of precision and recall. This takes the contribution of each, therefore the higher the F1 score, the better. See that because of the product within the dividend if one goes low, the ultimate F1 score goes down considerably. therefore a model will well in F1 score if the positive predicted are literally positives (precision) and does not miss out on positives and predicts them negative (recall).

One downside is that each precision and recall are given equal importance because of that consistent with our application we have a tendency to may have one on top of the opposite and the F1 score might not be the precise metric for it. so either a weighted-F1 score or seeing the PR or mythical creature curve will facilitate.
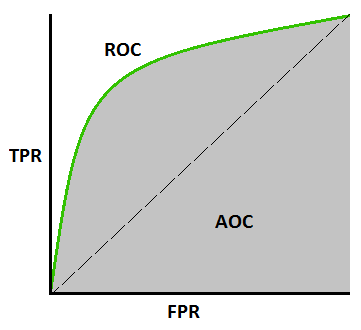
8. ROC Curve
ROC Curves show an exchange between Truth Positive Rate (TPR or Recall) and therefore the False Positive Rate (FPR). it’s established from the formulas on top of, TPR and FPR are nothing however sensitivity and (1 — specificity), therefore it may be checked out as a trade-off between sensitivity and specificity. The plot between the true positive rate against the false positive rate is thought of because of the mythical creature curve. As you’ll be able to see from the below sample graph, for higher values of TPR, you may even have higher values of FPR, which could not be sensible. therefore it’s all regarding finding a balance between these 2 metrics. a decent mythical creature curve is that the one that touches the upper-left corner of the graph; therefore the higher the world underneath the curve(AUC) of a mythical creature curve, the higher is your model.

9. AUC (Area under Curve)
AUC may be a completely different sort of metric. It measures the power of the model to predict a better score for positive examples as compared to negative examples. it’s freelance of the chosen threshold, you’ll be able to get away from the prediction performance of your model from the AUC metric while not choosing a threshold. If the roc curve is additional towards the upper-left corner of the graph, it means the model is incredibly sensible.
![]() 10. RMSE
10. RMSE
 10. RMSE
10. RMSERoot Mean Square Error (RMSE) is the standard deviation of the residuals (prediction errors). Residuals are a life of however removed from the curve information points are; RMSE may be a measure of however displayed these residuals are. In different words, it tells you ways focused the data is around the line of the best match. Root mean square error is usually utilized in meteorology, foretelling, and regression analysis to verify experimental results
The formula is:
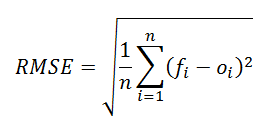 Where:
Where:
- f = forecasts (expected values or unknown results),
- o = observed values (known results).
- n = Total number of observations.
11. R-Squared (R²)
R-squared may be applied math live that represents the proportion of the variance for a variable that’s explained by AN variable or variables in an exceedingly regression model. R-squared values vary from zero to one and are ordinarily explicit as percentages from third to 100%. an R-squared of 100% means all movements of a variable are fully explained by movements within the freelance variable(s). it’s conjointly referred to as the Coefficient of Determination.
![R-squared - Machine Learning with Apache Spark Quick Start Guide [Book]](http://www.oreilly.com/library/view/machine-learning-with/9781789346565/assets/8baa308e-d8df-4565-bcc7-2b0b5bd2d866.png)
Where :
- SSE = Residual(Predicted Error) sum of squares
- SST = Total sum of squares
Related/References
- DP 100 Exam | Microsoft Certified Azure Data Scientist Associate
- Step By Step Activity Guides (Hands-On Labs) for DP-100 certification
- Microsoft Azure AI Fundamentals – AI-900 Exam Detailed Overview
- Microsoft Azure Data Scientist DP-100 FAQ
- [DP-100] Design & Implement a Data Science Solution on Azure Question & Answers/Day 1 Live Session Review
- DP 100 Exam | Microsoft Certified Azure Data Scientist Associate
Next Task For You
To know more about the course, AI, ML, Data Science for beginners, why you should learn, Job opportunities, and what to study Including Hands-On labs you must perform to clear [DP-100] Microsoft Azure Data Scientist Associate Certification register for our FREE CLASS.

The post Ways To Evaluate Machine Learning Model Performance appeared first on Cloud Training Program.